
단층 퍼셉트론과 AND, NAND, OR gate 구현
카테고리: DL
1. Perceptron
perceptron은 다수의 신호를 입력(input)으로 받아 하나의 신호를 출력(output)하는 개념으로, 딥러닝 신경망의 기원이 되는 알고리즘이다.
퍼셉트론은 신호를 통해 정보를 앞으로 전달하며 정보의 흐름을 만드는데, 이때 신호는 ‘흐른다(1)’, ‘안 흐른다(0)’의 두 가지 값을 가진다.
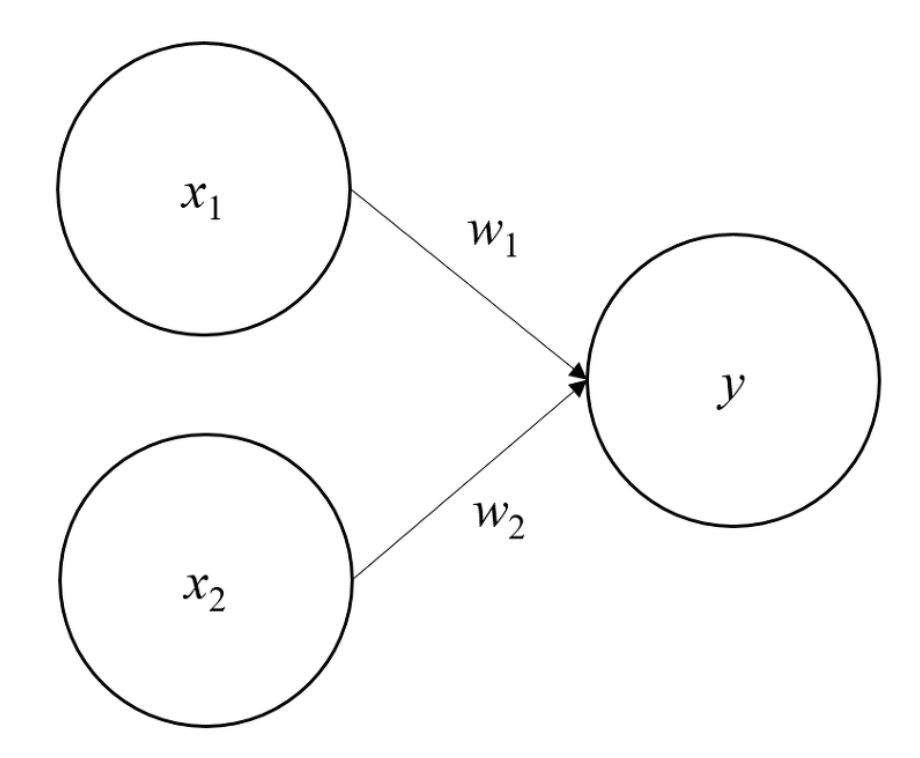 위 그림은 input으로 2개의 신호를 받은 perceptron의 예이다.
위 그림은 input으로 2개의 신호를 받은 perceptron의 예이다.
\(x_1, x_2\) : input signal
\(y\) : output signal
\(w_1, w_2\) : 가중치(weight)
기본 식은 \(y = wx + b\)의 1차 방적식이다.
입력 신호(\(x\))가 각 뉴런(이하 노드)에 전달될 때, 각각 고유한 가중치(\(w\))가 곱해진다.
가중치가 곱해진 값들의 합인 가중합이 특정 한계를 넘어설 때 ‘1’을 출력한다.(이를 ‘뉴런이 활성화한다’라고 표현하기도 한다)
그 특정 한계를 ‘임계값’이라 하며, \(θ\) 기호 (theta, 세타)로 나타낸다.
\(b + w_1x_1 + w_2x_2\) : 가중합(weighted sum)
퍼셉트론의 가중치가 클수록 강한 신호를 흘려보낸다.
2. Logic gate
2.1. AND GATE
AND gate 진리표
| \(x_1\) | \(x_2\) | \(y\) |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 1 | 1 |
AND gate를 perceptron으로 표현하고자 한다면, 위 진리표를 만족하는 \(w_1, w_2, θ\) 값을 정하면 된다.
ex_ \((w_1, w_2, θ) = (0.4, 0.4, 0.7) or (0.5, 0.5, 0.9) or (1.0, 1.0, 1.0)\) 인 경우에 모두 AND gate 조건을 만족
즉, 매개변수를 설정했을 때 \(x_1\)과 \(x_2\)가 모두 \(1\)일 때만 가중 신호의 총합이 임계값을 넘는다.
2.2. NAND GATE
NAND gate 진리표
| \(x_1\) | \(x_2\) | \(y\) |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 1 | 0 |
NAND는 Not AND이고, 이 의미는 AND gate 출력을 뒤집은 것이다.
위의 AND gate에서는 \(x_1, x_2\)가 모두 1일 때만 1을 출력했지만 NAND는 그 반대로 \(x_1, x_2\)가 모두 1일 때는 0을 출력하고, 나머지는 모두 1을 출력
AND gate의 모든 매개변수 부호를 반전시키면 NAND gate가 된다.
앞서 AND gate의 예로 든 매개변수의 부호만 바꾸면 NAND gate 진리표를 만족
\((w_1, w_2, θ) = (0.4, 0.4, 0.7) or (0.5, 0.5, 0.9) or (1.0, 1.0, 1.0)\)
==> \((w_1, w_2, θ) = (-0.4, -0.4, -0.7) or (-0.5, -0.5, -0.9) or (-1.0, -1.0, -1.0)\)
2.3. OR GATE
OR gate 진리표
| \(x_1\) | \(x_2\) | \(y\) |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 1 | 1 |
OR gate는 입력 신호(\(x_1, x_2\)) 중 하나 이상이 1 값을 가지면 1을 출력한다.
매개변수를 정하는 것은 컴퓨터가 아닌 인간이고, 직접 진리표라는 ‘train data’를 보면서 매개변수 값을 정한다.
‘기계 학습(Machine learning)’이라는 것은 이 매개변수를 컴퓨터가 알아서 정하도록 하는 것이다.
즉, 학습이란 적절한 매개변수를 정하는 과정이라고 할 수 있다.
perceptron의 구조는 AND, NAND, OR gate에서 모두 동일하고, 각 gate에서 상이한 것은 매개변수(가중치, 임계값)다.
3. 구현
import numpy as np
class Perceptron(object):
"""
eta : float, 학습률
n_iter : int
random_state : int
w_ : 1d-array
errors_ : list
"""
def __init__(self, eta = 0.01, n_iter = 50, random_state = 1):
self.eta = eta
self.n_iter = n_iter
self.random_state = random_state
"""
X : {array-like}, shape = [n_samples, n_feaures] -> {}안에 데이터, n_samples개 샘플과 n_features개의 특성, 훈련데이터
y : array-like, shape = [n_samples] -> {}안에 데이터, n_samples개의 정답 타깃
"""
def fit(self, X, y):
rgen = np.random.RandomState(self.random_state)
self.w_ = rgen.normal(loc = 0.0, scale = 0.01, size = 1 + X.shape[1])
self.errors_ = []
for _ in range(self.n_iter):
errors = 0
for xi, target in zip(X, y):
update = self.eta * (target - self.predict(xi))
self.w_[1:] += update * xi
self.w_[0] += update
errors += int(update != 0.0)
self.errors.append(errors)
return self
def net_input(self, X):
return np.dot(X, self.w_[1:] + self.w_[0])
def predict(self, X):
return np.where(self.net_input(X) >= 0.0, 1, -1)
먼저, fit 함수에서 self.w_ 로 표현된 가중치는 벡터 \(R^(m+1)\)로 초기화된다.
m은 데이터 셋의 차원을 뜻한다.
2차원 데이터라면 초기 self.w_는 \(R^3\)로 초기화된다.
size에 X의 개수보다 1을 더한 이유는 self.w_[0] = 절편(b)을 만들기 위함이다.
fit 에서 쓰이고 있는 self.w_벡터는 rgen.normal(loc = 0.0, scale=0.01, size = 1+X.shape[1])로 표준편차(scale)이 0.01인 정규분포에서 뽑은 랜덤한 작은 수를 담고 있고 이 수로 가중치를 초기화한다.사실 정규분포인 것도, 0.01인 것도 크게 의미는 없다.
쓰인 rgen함수는 numpy에서 제공하는 난수 생성기로, 시드를 통해 값을 제공하기 때문에 이전과 같은 결과가 계속 나올 수 있다.
가중치를 처음에 0으로 초기화하지 않는 이유는 가중치를 0으로 초기화하면 학습률이 가중치 벡터의 방향이 아닌 크기에만 영향을 미치기 때문이다.
fit 메서드는 가중치를 초기화한 후 X에 있는 모든 샘플에 가중치를 업데이트 한다.
이 훈련 샘플이 어느 클래스인지는 predict 메서드에서 예측한다.
이 과정을 반복하면서 epoch마다 self.errors_ 리스트에 잘못 분류된 횟수를 기록한다.